CASE STUDY 1: 신용카드 사용자 정보 그래프 시각화하기②
matplotlib 실행하기
우선 그래프 생성을 위해 운영체제별 폰트매니저를
지정하고 주요 칼럼별로 데이터 시각화를 진행하겠습니다.

1. 신용카드 사용자 나이 분포도

age칼럼의 빈도수(중복갯수)대로 .plot을 사용해
그래프화하였습니다.
.reset_index(drop=True)는 인덱스 재설정, 기존 인덱스 제거하는 의미.
도출된 그래프에 정보를 명확히 식별하기 어려워
히스토그램을 다시 활용해 보았습니다.

어느 연령대에 사용자가 많은지 확인이 더 용이해졌지만,
그래프의 구분 선이 명확하지 않아
한번 더 처리해주었습니다.

구체적인 범위설정, x바, y바, 제목까지 붙여보았을 때,
사용자 수가 가장 많은 주 사용자는 30~40대라는 것을 알 수 있습니다.
2. 신용카드 사용자의 직업 분포도
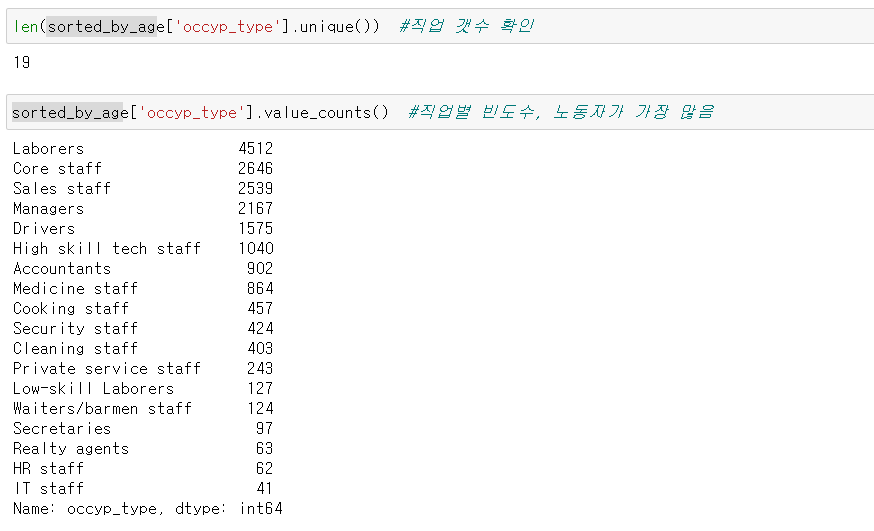
사용자 직업의 고유값이 몇 개인지 확인하기 위해 .unique()함수로 고유값을 출력한 후,
len()함수로 갯수를 확인하였습니다.
occyp_type 칼럼에서 고유값의 갯수가
19개라는 것을 확인하였습니다.
.value_counts() 는 고유값과 반복되는 값의 갯수를
나타내는 것으로 고유값이 총 18개인 것을
확인할 수 있습니다.
갯수 차이가 나는 이유는 계측치가 존재하기 때문입니다.
앞서, 계측치는 무직인 경우로 제외하였습니다.

이후 아까와 마찬가지로 가장 간단하게 .plot()을 사용하여 그래프를 확인했습니다.
대부분의 직업명이 나오지 않아 바그래프로 형식을 바꾸어 나타냈습니다.

barh 형식으로 확인하니 노동자가 직업 타입으로
가장 많다는 것을 알 수 있습니다.
3. 신용카드 사용자 교육수준 분포도


교육수준에 대해서도 바 그래프를 확인하여 가장 많은 항목을 확인하여 기본적인 사용자 데이터의 빈도수를 그래프로
파악할 수 있었습니다.
각 주요 칼럼을 확인하였으면 그룹별로 묶어 기초통계량을
확인하도록 하겠습니다.